
 Momentan (18.11.2025, gegen 12:00 Uhr) dürfte das "halbe" Internet gestört sein, denn der Dienst des Content Delivery Network Cloudflare ist ausgefallen. Mir waren die ersten Probleme bereits am Vormittag begegnet, ohne dass ich die Ursache erkannte, sondern ich ging von lokalen Störungen bei bestimmten Servern aus. Nachfolgend eine Übersicht, was bekannt ist. Ergänzung: Bericht von Cloudflare zur Ursache des weltweiten Ausfalls nachgereicht.
Momentan (18.11.2025, gegen 12:00 Uhr) dürfte das "halbe" Internet gestört sein, denn der Dienst des Content Delivery Network Cloudflare ist ausgefallen. Mir waren die ersten Probleme bereits am Vormittag begegnet, ohne dass ich die Ursache erkannte, sondern ich ging von lokalen Störungen bei bestimmten Servern aus. Nachfolgend eine Übersicht, was bekannt ist. Ergänzung: Bericht von Cloudflare zur Ursache des weltweiten Ausfalls nachgereicht.
Ich habe es erst gar nicht realisiert, als ich heute Vormitteag, beim Versuch, eine CVE-Nummer nachzuschauen, eine "Internal Server Error"-Meldung bekam. Nachdem ich dann bei Bleeping Computer auch vor dieser Meldung stand, habe ich doch mal genauer geschaut. Nicht mal allestoerungen.de kannst Du noch aufrufen – da kam eine Meldung "Lassen Sie challanges.cloudflare.com zu, um fortzufahren", die mir sagte, dass ich Cloudflare zulassen solle – aber wie, wurde nicht gesagt.
allestörungen.de muckt gerade auch
Erst nach einer Minute oder länger kam dann bei allestoerungen.de die nachfolgende Störungsseite, die das Problem zeigt.
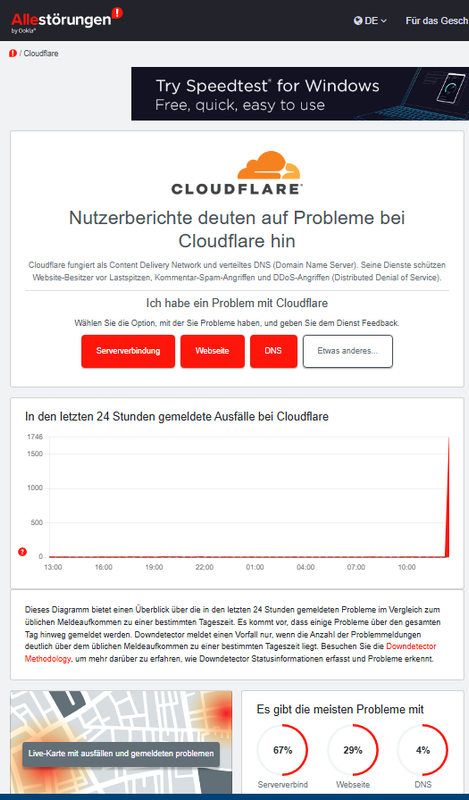
Seit kurz nach 12:00 Uhr nimmt die Zahl der Störungsmeldungen zu Cloudflare sprunghaft zu. Es ist eine internationale Störung, wie ich bei downdetector.com gesehen habe.
Cloudflare-Seitenbetreiber sind "offline"
Webseitenbetreiber, die Cloudflare als Content Delivery Network oder zur DDoS-Abwehr nutzen, schauen derzeit in die Röhre. Betroffene Seiten zeigen die nachfolgende Fehlerseite:
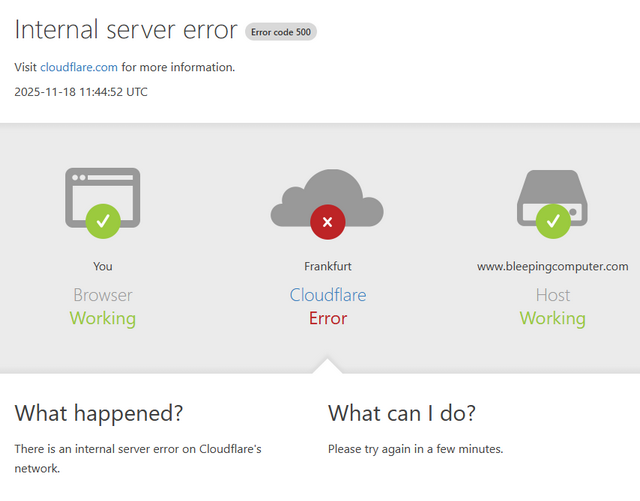
Obige Fehlerseite gehört zu Bleeping-Computer und sagt, dass Cloudflare in Frankfurt Fehler bringe. Auch The Register kann nicht abgerufen werden. Bei anderen Seiten bekomme ich plötzlich eine Anmeldeseite zu sehen. Kann man nix machen, ist halt Cloud(flare).
Cloudflare-Störungsmonitor zeigt Probleme
Der Cloudflare-Störungsmonitor muckt auch. Erst nach einer Wartezeit von einer Minuten kam folgende Anzeige – sieht mir alles nach einem Überlastungsangriff (DDoS) aus.
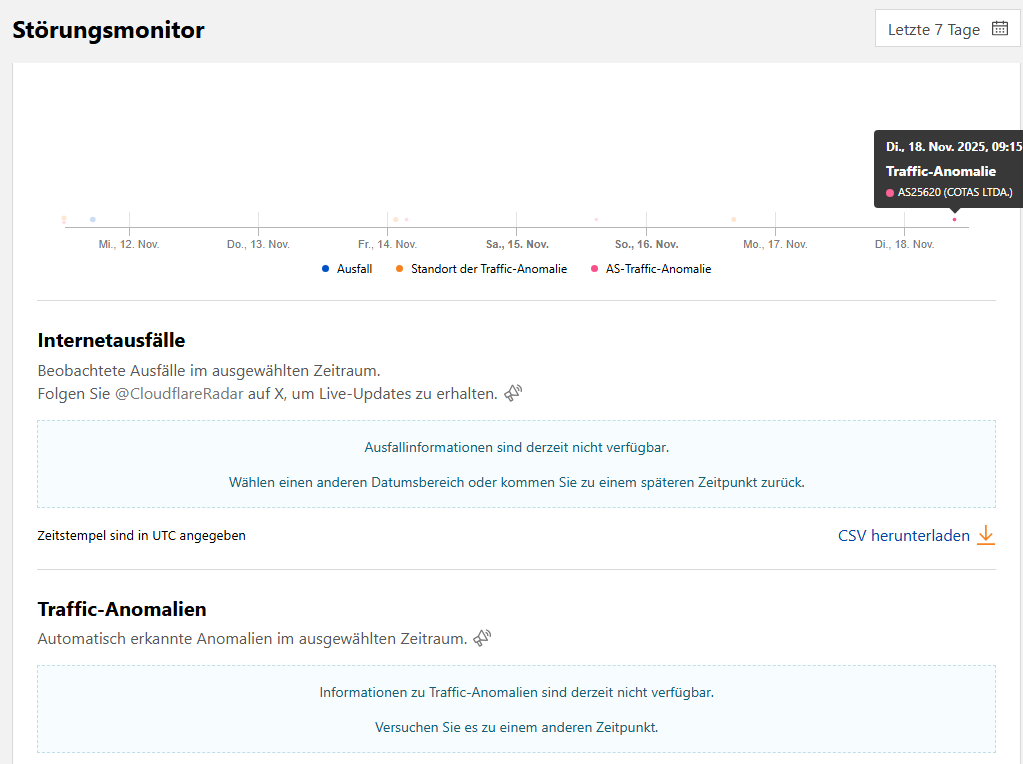
Dort wird eine Traffic-Anomalie seit 9:15 Uhr aufgeführt. Allerdings heißt es, dass keine Internetausfälle bekannt seien. Als ich dann auf den betreffenden Punkt für Details gegangen bin, bekam ich die folgende Anzeige:

Also auch dort kein wirkliches weiterkommen, was den Ausfall bzw. Hinweise dazu betrifft. Selbst auf X.com wird mir der Zugriff verweigert – dort heißt es kryptisch "Etwas ist schiefgelaufen. Probiere, es erneut zu laden." Update: Gerade hat mit X dann doch noch ein paar Nachrichten ausgespuckt – z.B. diese hier:
Cloudflare just had a brief worldwide outage – knocking off twitter and basically every site hosted on Cloudflare
Aktuell schätze ich, dass bei einigen Webseitenbetreibern, die Cloudflare als Content Delivery Network (CDN) zur Lastverteilung nutzen, die Telefone heiß laufen, weil nichts mehr geht. Ist jemand aus der Leserschaft betroffen?
Cloudflare Stellungnahme zum Ausfall
Inzwischen scheint das Problem behoben, und Cloudflare hat auf seiner Statusseite einige Informationen gepostet.
Cloudflare Global Network experiencing issues
Incident Report for Cloudflare
Update: The team is continuing to focus on restoring service post-fix. We are mitigating several issues that remain post-deployment.
Posted 1 minute ago. Nov 18, 2025 – 15:40 UTCUpdate: We are continuing to monitor for any further issues.
Posted 18 minutes ago. Nov 18, 2025 – 15:23 UTCUpdate: Some customers may be still experiencing issues logging into or using the Cloudflare dashboard. We are working on a fix to resolve this, and continuing to monitor for any further issues.
Posted 44 minutes ago. Nov 18, 2025 – 14:57 UTCMonitoring: A fix has been implemented and we believe the incident is now resolved. We are continuing to monitor for errors to ensure all services are back to normal.
Posted 59 minutes ago.
Nov 18, 2025 – 14:42 UTCUpdate: We've deployed a change which has restored dashboard services. We are still working to remediate broad application services impact
Posted 1 hour ago. Nov 18, 2025 – 14:34 UTCUpdate: We are continuing to work on a fix for this issue.
Posted 1 hour ago. Nov 18, 2025 – 14:22 UTCUpdate: We are continuing working on restoring service for application services customers.
Posted 2 hours ago. Nov 18, 2025 – 13:58 UTCUpdate: We are continuing working on restoring service for application services customers.
Posted 2 hours ago. Nov 18, 2025 – 13:35 UTCUpdate: We have made changes that have allowed Cloudflare Access and WARP to recover. Error levels for Access and WARP users have returned to pre-incident rates.
We have re-enabled WARP access in London.We are continuing to work towards restoring other services.
Posted 2 hours ago. Nov 18, 2025 – 13:13 UTC
IdentifiedThe issue has been identified and a fix is being implemented.
Posted 3 hours ago. Nov 18, 2025 – 13:09 UTCUpdate: During our attempts to remediate, we have disabled WARP access in London. Users in London trying to access the Internet via WARP will see a failure to connect.
Posted 3 hours ago. Nov 18, 2025 – 13:04 UTCUpdate: We are continuing to investigate this issue.
Posted 3 hours ago. Nov 18, 2025 – 12:53 UTCUpdate: We are continuing to investigate this issue.
Posted 3 hours ago. Nov 18, 2025 – 12:37 UTCUpdate: We are seeing services recover, but customers may continue to observe higher-than-normal error rates as we continue remediation efforts.
Posted 3 hours ago. Nov 18, 2025 – 12:21 UTCUpdate: We are continuing to investigate this issue.
Posted 4 hours ago. Nov 18, 2025 – 12:03 UTCInvestigating: Cloudflare is experiencing an internal service degradation. Some services may be intermittently impacted. We are focused on restoring service. We will update as we are able to remediate. More updates to follow shortly.
Posted 4 hours ago. Nov 18, 2025 – 11:48 UTC
Dane Knecht, CEO von Cloudflare hat auf X das nachfolgende Statement gepostet.
I won't mince words: earlier today we failed our customers and the broader Internet when a problem in @Cloudflare network impacted large amounts of traffic that rely on us. The sites, businesses, and organizations that rely on Cloudflare depend on us being available and I apologize for the impact that we caused.
Transparency about what happened matters, and we plan to share a breakdown with more details in a few hours. In short, a latent bug in a service underpinning our bot mitigation capability started to crash after a routine configuration change we made. That cascaded into a broad degradation to our network and other services.
This was not an attack. That issue, impact it caused, and time to resolution is unacceptable. Work is already underway to make sure it does not happen again, but I know it caused real pain today. The trust our customers place in us is what we value the most and we are going to do what it takes to earn that back.
Der CEO von Wire erläutert dazu, wieso sich Unternehmen jetzt von der Hyperscaler-Monokultur lösen müssen:
Der Cloudflare-Ausfall zeigt, wie stark das Internet von nur wenigen zentralen Infrastruktur-Anbietern abhängt. Wenn ein zentraler Netzdienst wie Cloudflare – der vor Millionen von Websites und Apps geschaltet ist – eine Störung hat, sind Kommunikation, Transaktionen und ganze digitale Dienste innerhalb von Minuten betroffen.
Das macht eines deutlich: Für jede Organisation ist es keine tragfähige Strategie mehr, sich für kritische Funktionen allein auf einen einzelnen Anbieter zu verlassen. Da in den vergangenen Wochen nicht nur Cloudflare, sondern auch große Anbieter wie AWS massive Ausfälle hatten, bedeutet echte Resilienz, wirkliche architektonische Alternativen zu haben und digitale Souveränität über die eigenen Kernprozesse zu gewinnen.
Die Frage, die sich Führungskräfte stellen sollten, lautet daher nicht, ob der nächste große Ausfall kommt, sondern wie ihr Unternehmen funktionieren wird, wenn er eintritt. Sich von dieser Hyperscaler-Monokultur zu lösen, ist die einzig logische Antwort.
Blogs auf borncity ebenfalls kurz down
Abseits der obigen Problematik musste ich feststellen, dass meine Blogs auf borncity.com sowie auf borncity.eu ebenfalls zeitweise nicht erreichbar waren. Dabei nutze ich kein Cloudflare. Irgendwelche WordPress Plugins, die Cloudflare nutzen, schließe ich aus, da die Startseiten auf borncity.com und borncity.eu jeweils statischen Webseiten sind.
Der Server des Hosters all-inkl.com war erreichbar, und ich kam in der Weboberfläche sogar auf die Dateien des FTP-Bereichs. Ich hatte bei all-inkl.com nachgefragt und bekam vom Support folgende Rückmeldung:
Mit ziemlicher Wahrscheinlichkeit liegt dies an dem aktuellen Cloudflare-Problem (siehe https://www.cloudflarestatus.com/)'
Ich kann bei mir beiden Seiten problemlos aufrufen und bekomme auch einen ordentlichen Inhalt angezeigt.
Jetzt frage ich mich, wie der Ausfall erklärt werden kann? Ergänzung: Der Screenshot von folgendem Bild erklärt es dann vermutlich.
Erklärung von Cloudflare zum Problem
Hier als Nachtrag der Post-Incident-Bericht von Cloudflare zur Ursache des Ausfalls: Cloudflare outage on November 18, 2025. Das Problem wurde weder direkt noch indirekt durch einen Cyberangriff oder böswillige Aktivitäten jeglicher Art verursacht. Vielmehr wurde es durch eine Änderung der Berechtigungen eines der von Cloudflare verwendeten Datenbanksysteme ausgelöst.
Dadurch schrieb die Datenbank mehrere Einträge in eine vom Cloudflare Bot-Management-System verwendete "Feature-Datei". Diese Feature-Datei verdoppelte sich daraufhin in ihrer Größe. Die größer als erwartete Feature-Datei wurde dann an alle Rechner weitergegeben, aus denen unser Netzwerk besteht.
Die Software, die auf diesen Cloudflare-Rechnern läuft, um den Datenverkehr im Netzwerk zu leiten, greift auf diese Feature-Datei zu, um das Cloudflare Bot-Management-System angesichts der sich ständig ändernden Bedrohungen auf dem neuesten Stand zu halten. Die Software hatte eine Begrenzung für die Größe der Feature-Datei. Als die Feature-Datei zu groß wurde, fiel diese Software schlicht aus, was dann die betreffenden Probleme verursachte.









LOL
Allesstörungen.de geht auch nicht
"Lassen Sie challenges.cloudflare.com zu, um fortzufahren"
Ging mir vorhin auch so weiß garnicht mehr bei welcher Seite. Aber wird schon bald wieder gehen.
allestörungen.de geht hier aber auch nicht, denn das will challenges.cloudflare.com aufrufen. So schließt sich der Kreis.
Eventuell mal wieder ein DDoS?
inzwischen geht es
Joa, ist mal wieder alles im Eimer.
Jo, für die URL "allestoerungen.de" wird anscheinend erstmal auf ein beim Cloudflare London-Knoten liegendes Problem verwiesen.
Den Verweis auf "challenges.cloudflare.com" erhalte ich nur unter "allestörungen.de" (IDN).
Ansonsten gibt's ja einige Auskünfte bei https://www.cloudflarestatus.com/
Ging gestern früh kurz vor 8 schon los
Wie man das Internet im Jahr 2025 lahm legt:
Schritt 1: AWS geht down
Schritt 2: Cloudflare geht down
Fertig.
Da fehlt noch die dritte Variante, die russische. Eine fette Bombe auf Frankfurt-Ost. So wie sich das dort mit den vielen Rechenzentren entwickelt, das wird ein Single-Point-of-Failure.
o365 geht ;) auch Entra ID etc.
Ja, wir haben Web Seiten via Cloudflare, die gehen im Moment nicht. Unter cloudflarestatus.com ist dies mittlerweile auch dokumentiert.
Und jede Webseite/Dienst usw. hierzulande, die jetzt nicht geht, ist sich hoffentlich bewusst, dass sie von einer US Firma abhängig ist, für die der US Cloud Act gilt.
… hier das gleiche, nur wird der Knoten Amsterdam als Störungspunkt angezeigt.
Zwischenzeitlich ging es mal kurz, so dass ich eine Datei über transfernow versenden konnte, dann wieder Ausfall und aktuell 13:20 läuft wieder alles.
Thunderbird Release Seite konnte auch nicht aufgerufen werden und zeigte die gleiche Meldung wie im Bild des Artikels.
Die bekommen wohl gerade das neueste Windows 11 Update 😵💫😀
:)
Bei mir funktionieren Bleeping Computer und andere Seiten ganz normal.
Vielleicht liegt das bei euch an einem DNS-Problem, denn bei mir läuft Technitium DNS Server mit lokaler DNS-Root-Server-Kopie.
Wenn ich allerdings auf Cloudflare-DNS oder Google-DNS oder Quad9-DNS umschalte, dann funktionieren diese Seiten bei mir ebenfalls nicht mehr. Mit OpenDNS funktioniert es aktuell auch, aber nur sehr langsam.
Aus diesem Grund kann ich den Technitium DNS Server nur empfehlen.
Der ist kostenlos und DNS-Probleme sind dann Vergangenheit.
Erstaunlicherweise kommt dieser DNS-Server aktuell bei mir mit 110 MB RAM aus. Ich hatte eigentlich erwartet, dass die DNS-Datenbank wesentlich größer wäre. Vielleicht habe ich etwas falsch (oder besonders effizient) eingestellt, aber es funktioniert.
Technitium ist cool, aber auch nur ein Einmann-Projekt.
Unbound ist Rock solid und im Docker ~ 60mb ram
Das sah mir hier nicht nach einem DNS-Problem aus, allestörungen.de wollte immer die Seite challenges.cloudflare.com laden, diese typische "Ich bin ein Mensch und kein Roboter" Checkbox. Die Seite reagierte eine zeitlang nicht, dann sehr träge und wackelig, mittlerweile wohl wieder besser.
Auf der Cloudflare-Status-Seite steht was zu geplanten Wartungsarbeiten, die aktuell laufen (LAX, PPT, SCL, ATL). Vielleicht ist dabei was schief gelaufen und die haben Routen falsch gesetzt bzw. bis zum Ausfall überlastet?
Es ist auch kein DNS-Problem, aber CloudFlare benutzt (natürlich) Geo-DNS. Wenn du also einen DNS nutzt, der bspw. in den USA "sitzt", aber nur europäische Cloudflare-Server betroffen sind, kann man das Problem damit "umgehen".
Diese Meldung "challenges.cloudflare.com" bei allestoerungen.de kam um ca 14:15 Uhr bei mir auch. Vorhin bis ca 14:10 Uhr ging es noch problemlos.
Um 15:08 Uhr meldet Allesstoerungen:
Internal server error
There is an internal server error on Cloudflare's network.
Ray ID: 9a0809486c9bf813
Your IP address: XXXX
Error reference number: 500
Cloudflare Location: Düsseldorf
Bleepingcomputer.com geht seit ca 14:15 auch nicht mehr.
Cloudflare Error (zuerst Amsterdam, danach Düsseldorf)
Das Cloudflare-Problem weitet sich aus, weil mehr Cloudflare-Server ausfallen, die eben noch liefen.
Dann liegt es wohl doch nicht am DNS.
Fehler auch auf:
B0rncity. com (von 14:30 bis 14:57 Uhr nicht erreichbar)
forums. mydigitallife. net
pcgameshardware. de
isitdownorjustme. net
serienfans. org
mygully. com
nicht betroffen:
Medien wie ARD, ZDF, Bild, Welt, Focus, Zeit
Heise-Forum
Computerbase
Winfuture
Deskmodder
Bluesky
Amazon
Reddit
Bei Spiegel geht kein HTTPs, nur HTTP, aber das könnte ein anderes Problem sein.
CDNs sind eine Gefahr für das Internet und gehören verboten.
hier ist auch alles normal.
Alle eigenen Seiten via CF laufen,
allestörungen geht auch ohne Probleme
>>> die Telefone heiß laufen, weil nichts mehr geht. Ist jemand aus der Leserschaft betroffen?
Die gehen doch alle heutzutage über IP sind auch Down ;)
Ich habe gestern schon bei einem Kunden lange nach Fehlern gesucht. Problem war: Bei allen Usern, egal ob per App oder im Browser wurde in Teams Kanälen im Reiter "Dateien" nichts mehr angezeigt. Gar nichts, auch nicht die Kopfzeile mit "Neu" etc.. Im dahinterliegenden SharePoint war alles da. In privaten Kanälen wurden die Dateien normal angezeigt. In allen "Standard" Kanälen nichts.
Nach einigem probieren und testen nach ca. 2-3h waren die Dateien plötzlich bei allen wieder normal sichtbar. Ohne eine Änderung am Tennant durchgeführt zu haben.
Heute ein ähnliches Problem bei einem anderen Kunden. Der Reiter "Dateien" in Teams heißt plötzlich "Freigegebene" und synct nicht via OneDrive im Windows Explorer. Dateien, die in Teams abgelegt werden, werden im Explorer nicht angezeigt. Kurz getestet und OneDrive Pause & Resume, lokal eine Datei abgelegt: Wird in Teams angezeigt und plötzlich auch die Dateien aus Teams lokal angezeigt. Also erst mal wieder ok.
Keine Ahnung, ob es hiermit zusammenhängt, aber in dem Bereich scheint es seit gestern auch Probleme zu geben….
Lernt der Kunde denn wenigstens auch daraus, dass jederzeit Inhalte in Teams usw. einfach mal verschwinden können? Und ggf. auch nicht wieder auftauchen?
Vorweg ich bin kein ITler ich lese hier als interessierter Anwender einfach mit. Wir hatten letzte Woche ein ähnliches Problem mit MS Teams. Wir konnten Dateien und geteilte Screenshots nicht sehen. Neustart des Rechners hat nicht geholfen. Bei uns hat geholfen das wir uns aus MS Teams ausgeloggt und dann wieder eingeloggt haben. Seitdem haben wir keine Probleme mehr gehabt.
Seit ca. 13:00 Uhr wird mir dieser Quatsch ebenfalls angezeigt. Bin entsprechend angefressen…
Habe mich schon gewundert was los ist.
Kannte dieses CloudFlare nicht und sagte mir gar nichts.
Ist echt nervig, aber doch beruhigend dass ich nicht der einzige bin.
Tja, ChatGPT geht auch nicht mehr. Unsere eigene Website auch nicht (OnlineShop). Gab es sowas in der Vergangenheit schon einmal? Wir sind erst seit 1 Monat bei Cloudflare.
Kommt gelegentlich vor.
Und warum seid ihr bei Cloudflare? Um euch extern abhängig zu machen? Und gleichzeitig alle euere und Kundendaten via US Cloud Act in die USA zu liefern?
Nichts wie weg da.
Also wir sind schon seit Jahren bei Cloudflare und so einen Unterbruch hatten wir jetzt noch nie. Grund für Cloudflare ist hauptsächlich die Abwehr von DDOS Attacken. Wir haben jetzt via DNS Cloudflare temporär rausgenommen, die Webeiten funktionieren jetzt wieder.
Ich denke, man sollte sich für solche Fälle einen Plan machen, wie man schnell umschalten kann.
Ja, ist bei mir auch gleichermaßen vorhanden. Egal was ich mache. Ich stolpere ständig über diese Meldung. Woran ann das liegen? Stromausfall? Auf der Fehlermeldung wird nur Amsterdam als Serverstandort genannt.
nichmal lieferando geht.
kannst dir nichtmal ne pizza grad in deutschland bestellen, nurnoch per telefon.
au backe… So beginnt das armageddon
Lassen sie challenge.cloundflare.com zu.
Und Heise meldet Stadtwerke Detmold nicht mehr erreichbar.
h**ps://www.heise.de/news/Stadtwerke-Detmold-nach-IT-Vorfall-offline-11082906.html?wt_mc=rss.red.ho.ho.atom.beitrag.beitrag
Hängt evtl. auch damit zusammen. Oder sie haben auch eine Störung.
Die leiden an den Folgen des "never touch a running system" Syndroms.
Lieferando ebenfalls davon betroffen.
Schaut man sich die Cloudflare Statuspage an und liest etwas weiter, dann sieht es wie eine schiefgelaufene Wartungsmaßnahme aus. Die Data Center in Santiago de Chile, Tahiti, Atlanta und Los Angeles verzeichnen alle für heute Wartungsmaßnahmen. Vielleicht ein Ketteneffekt der sich dann global ausgebreitet hat.
https://www.cloudflarestatus.com/
„ SCL (Santiago) on 2025-11-18
In progress – Scheduled maintenance is currently in progress. We will provide updates as necessary.
Nov 18, 2025 – 12:02 UTC
Scheduled – We will be performing scheduled maintenance in SCL (Santiago) datacenter on 2025-11-18 between 12:00 and 15:00 UTC.
Traffic might be re-routed from this location, hence there is a possibility of a slight increase in latency during this maintenance window for end-users in the affected region. For PNI / CNI customers connecting with us in this location, please make sure you are expecting this traffic to fail over elsewhere during this maintenance window as network interfaces in this datacentre may become temporarily unavailable.
You can now subscribe to these notifications via Cloudflare dashboard and receive these updates directly via email, PagerDuty and webhooks (based on your plan): https://developers.cloudflare.com/notifications/notification-available/#cloudflare-status.
Nov 18, 2025 12:00-15:00 UTC
PPT (Tahiti) on 2025-11-18
In progress – Scheduled maintenance is currently in progress. We will provide updates as necessary.
Nov 18, 2025 – 12:00 UTC
Scheduled – We will be performing scheduled maintenance in PPT (Tahiti) datacenter on 2025-11-18 between 12:00 and 16:00 UTC.
Traffic might be re-routed from this location, hence there is a possibility of a slight increase in latency during this maintenance window for end-users in the affected region. For PNI / CNI customers connecting with us in this location, please make sure you are expecting this traffic to fail over elsewhere during this maintenance window as network interfaces in this datacentre may become temporarily unavailable.
You can now subscribe to these notifications via Cloudflare dashboard and receive these updates directly via email, PagerDuty and webhooks (based on your plan): https://developers.cloudflare.com/notifications/notification-available/#cloudflare-status.
Nov 18, 2025 12:00-16:00 UTC
LAX (Los Angeles) on 2025-11-18
In progress – Scheduled maintenance is currently in progress. We will provide updates as necessary.
Nov 18, 2025 – 10:00 UTC
Scheduled – We will be performing scheduled maintenance in LAX (Los Angeles) datacenter on 2025-11-18 between 10:00 and 14:00 UTC.
Traffic might be re-routed from this location, hence there is a possibility of a slight increase in latency during this maintenance window for end-users in the affected region. For PNI / CNI customers connecting with us in this location, please make sure you are expecting this traffic to fail over elsewhere during this maintenance window as network interfaces in this datacentre may become temporarily unavailable.
You can now subscribe to these notifications via Cloudflare dashboard and receive these updates directly via email, PagerDuty and webhooks (based on your plan): https://developers.cloudflare.com/notifications/notification-available/#cloudflare-status.
Nov 18, 2025 10:00-14:00 UTC
ATL (Atlanta) on 2025-11-18
In progress – Scheduled maintenance is currently in progress. We will provide updates as necessary.
Nov 18, 2025 – 07:02 UTC
Scheduled – We will be performing scheduled maintenance in ATL (Atlanta) datacenter between 2025-11-18 07:00 and 2025-11-19 22:00 UTC.
Traffic might be re-routed from this location, hence there is a possibility of a slight increase in latency during this maintenance window for end-users in the affected region. For PNI / CNI customers connecting with us in this location, please make sure you are expecting this traffic to fail over elsewhere during this maintenance window as network interfaces in this datacentre may become temporarily unavailable.
You can now subscribe to these notifications via Cloudflare dashboard and receive these updates directly via email, PagerDuty and webhooks (based on your plan): https://developers.cloudflare.com/notifications/notification-available/#cloudflare-status.
Nov 18, 2025 07:00 – Nov 19, 2025 22:00 UTC"
1und1 Kundenlogin funktioniert nicht, ChatGPT funktioniert nicht etc. Bekomme auch die Seite mit Cloudeflare zulassen angezeigt. Kindelbück in Thüringen.
Denke das wars für CF – davon erholen Sie sich nicht mehr
😂 Sowas mußt Du doch bitte unbedingt als "Ironie" kennzeichnen.
Oh, da wird sich jetzt aber auch ein Spam Versender in den Allerwertesten beißen, der die Empfänger mit einer gefakten GLS Paketnummer zu irgendeiner Zahlung bringen will. Der betreibt seine Betrugsseite nämlich auch über Cloudflare. Pech für den Betrüger, Glück für einige zu leichtgläubige Empfänger.
BTW: Dieser Blog läuft übrigens bei mir in Wien auch nicht ganz rund und sehr lahm.
X zickt hier auch
Synology Downloads funktionieren auch nicht
pcgameshardware läuft auch nicht
Der Blog selbst zickt auch gerade etwas.
Ja, borncity.com war auch für eine Weile nicht erreichbar.
Ja, ich sehe, dass ich den Blog nicht erreichen kann – aber auf den FTP-Bereich drauf kann. Da ich kein Cloudflare nutze, muss es noch andere Probleme geben. Auch der Postillon ist offline. Ich gehe Schuhe putzen.
Der Blog ist einfach so beliebt und gefragt, dass die Nutzer auf der Suche nach Infos zum Cloudflare-Problem den Blog kurz geDDOSt haben.
Es war schon mächtig was los – der Beitrag hier steht kurz unter 25.000 Abrufen.
Mal sehen, ich stelle gerade die Weichen, dass der Blog auch die kommenden Jahre noch lebt – da kommt dann vermutlich auch ein anderer Unterbau ins Haus. Hoffe, dass ich bis Jahresende alles klar gemacht habe.
Schon sehr bedenklich was da alles dran hängt…
Das Schlimmste:
Postillon und Bildblog gehen (zumindest bei mir) nicht!
Auch diese Artikel-Unterseite hatte gerade gezickt. Die Werbung ist nicht sichtbar. Ich vermute der Fehler kam durch die Werbung. Fehlermeldung habe ich mir leider nicht gemerkt und beim zweiten Versuch ging es dann gleich wieder (aber wie oben erwähnt ohne Werbungsanzeige – trotz keinem Adblocker)
Liegt bestimmt am neuen Vodafone peering *hust* :-)
Geht in die (K)Cloud sagten sie…
Zentralisiert das INTERNET hinter CLOUDFLARE sagten sie…
Nutzt (angebliche) K.I. sagten sie – aber halt: die (angebliche) K.I. braucht ja CLOUDFLARE…hm
Nicht mal den Herrn Born kann CLOUDFLARE nun um Rat fragen, sowas unvorstellbares aber auch!
Jetzt mal im Ernst und Günter: privat funktioniert hier bei mir Stand 15:24 Uhr so gut wie gar nichts mehr – und das liegt NICHT am DNS.
Garmin Connect ist nicht erreichbar
Ich bin mal gespannt wann einer mit den Finger auf die Russen zeigt, und dort das mit gewohnter Empörtheit quitiert wird. Die Russen naja vielleicht noch Nordkorea sind die einzigen die sich mittlerweile vom Rest der Welt abnabeln und sich einen Ast lachen wenn nichts mehr geht bei uns. Welcher clevere Mensch hat nochmal die IP Telefonie als Wahrheit letzter Schuss verkauft ? Weil mit Telefonieren iss nämlich dann auch Essig, komisch früher war das eher nicht so das Problem.
IP-Telefonie und Cloudflare, bitte erzähle mehr über diese große Sache, das wissen echt nur die Wenigsten…
Wir haben nun unsere DNS angepasst, sodass Cloudflare nicht mehr im Spiel ist. Die Webseiten funktionieren nun wieder. Wenn Cloudflare dann "grün" meldet, gehen wir wieder zurück.
Bringt aber nur was wenn die TTL nicht zu lang ist.
Nur blöd, dass Änderungen oft erst nach 1 oder 2 Stunden greifen. Die Idee hatte ich auch schon. Jetzt aber nicht mehr nötig. CF läuft wieder.
Welche Upstream-DNSe habt ihr denn jetzt gewählt?
Und jetzt nach DNS-Änderung ein DDOS direkt auf eure Seiten… Da steckt ein größerer Plan dahiner.
Jetzt stellen wir uns einmal vor, so eine Störung gäbe es bei AWS, Azure etc.
Und dann 2 Wochen lang.
Dann wird es weltweit eine Welle an Firmenpleiten ungeahnten Ausmasses geben.
Alle Firmen, die den Cloud-Wahn verfallen sind, werden dann pleite gehen.
Das Resultat wäre eine sehr schwere globale Wirtschaftskrise.
Der Börsencrash von 1929 wäre dagegen ein Sack Reis, der in China umgefallen ist.
Diese Cloudjünger merken gar nicht, wie die sich in die totale Abhängigkeit von fremden Diensten begeben und auch die Hoheit über ihre Daten abgeben.
Absolut richtig. Leider muss das auch mal so eintreten, damit die großen da draußen endlich aufwachen…
Es wird immer Abhängigkeiten geben, also was soll das? Es würde auch langen, wenn Internetknoten gestört werden und dann? Oder dein Internetprovider ist down oder…
Naja also ich kann auch ohne Internet produzieren ;-P Aufträge kann ich auch telefonisch annehmen und ist redundant und da nix in der Cloud hängt…
Problematisch wäre da nur Rohstoffe zu ordern, sollten die Aus gehen.
Mag sein das ich mit der Strategie nie zu den Großen aufschliessen werde, aber shice drauf ich kann sehr gut von Leben!
Und Dein Telefon bzw. das der Anrufer läuft nicht über VoIP?
der hat doch noch eine Trommel…tusch
Versand deiner Produkte?
Da kommt der Postman mit dem Elektrodreirad vorbei.
Genau!
Auch von diesen Dingen macht man sich abhängig, wenn man alles in die Cloud packt.
Genau deshalb gibt es hier in der Firma ausschließlich OnPrem.
Da kann auch das Internet komplett ausfallen, wir bleiben arbeitsfähig und haben vollen Zugriff auf unsere Daten und Anwendungen.
Und da bei uns die komplette Serverlandschaft redundant ist und wir für die kritischen Komponenten reichlich Ersatz im Schrank liegen haben kann uns auch der Ausfall eines OnPrem-Servers nicht lahm legen.
Und ja, auch Telefonie kann ausfallen.
Aber eine ausgefallene Telefonie legt nicht die Verwaltung und Produktion lahm.
Bei einen Ausfall der Cloud dagegen sehr wohl, weil die Leute einfach nicht mehr auf die Daten zugreifen können.
Wer sagt das man alles in die Cloud packt, nicht verstanden das deine Diensleister, Kunden und auch Versender das Internet nutzen? Willst du deine Produkte mit dem Esel ausliefern? Zahlungen tätigen, wie? Unglaublich diese Kurzsichtigkeit.
nicht gelesen oder verstanden?
"Bei einen Ausfall der Cloud dagegen sehr wohl, weil die Leute einfach nicht mehr auf die Daten zugreifen können."
Das könnte passieren, wenn man Email, Kontakte, Dokumente, Projektdaten in der Cloud (MS365, OneDrive, AWS etc.) hat.
Zur Not gibts noch die gute alte Post (hoffentlich aber kein Fax mehr ;-) ) -> wenn Dir das noch was sagt!
Der Gegenüber ist in dem Falle egal… weil der hat das ja gewählt!
Solche Dinge sind im ERP gespeichert und das sollte nicht in der Cloud sein. Falls dir das etwas sagt.
du findest immer einen Bogen… nicht zu fassen!
Aber: ein ERP hat z.B. keine CAD-Daten, keine internen Rechendaten (meist sehr groß) etc.
… falls Dir das was sagt! ;-)
Ach SvenS, wir haben Inventor, Vault etc. und das on-Prem und mir ich noch deutlich mehr bekannt aber ich spreche nicht für mich, sondern stelle mir vor wie andere das sehen könnten oder wir andere Unternehmen arbeiten könnten. Cloud ist beim uns nur ein kleiner Teil.
Und dann kommt der Bagger und kappt euch die Stromleitung…
Dadurch gehen die Daten aber nicht verloren.
Bei Strom weg springen redundante USVs ein und die starten dann, wenn nach 20 Minuten der Strom nicht wieder da ist, die Notstromaggregate an.
Dann kann zumindest die Verwaltung und Entwicklung weiter arbeiten.
Und Telefonieren geht dann per Handy/Smartphone, denn die Mobilfunkmasten haben i.d.R. eine eigene Stromzuführung.
Und wie lange hält dein Notstrom? Das wird hoffentlich regelmäßig getestet, nicht das es dann unerwartet Probleme gibt.
Wunschdenken und Wirklichkeit
15:45 Uhr MEZ:
Alle Seiten funktionieren wieder.
Cloudlfare-Status meldet:
A fix has been implemented and we believe the incident is now resolved. We are continuing to monitor for errors to ensure all services are back to normal.
Nov 18, 2025 – 14:42 UTC
2.
Erstaunlicherweise scheint die "Dark Reader" Erweiterung für Firefox auch betroffen zu sein, denn während des Cloudflare-Ausfalls war Winfuture weiß statt dunkel.
Seit 15:45 Uhr aber ist es wieder dunkel.
Edit:
Ein Admin von Winfuture bestätigt, dass die Bilder der Winfuture-Webseite bei Cloudflare liegen.
Nicht so wirklich.
dashboard.cloudflare.com geht noch nicht richtig
https://dash.cloudflare.com/login geht.
Ich konnte für die relevanten Seiten das Proxying über Cloudflare abschalten.
Ham wohl das Privat Peering mit Vodafone nicht bezahlt
Lacht, sehr schön.
Cloudflare Enterprise scheint nicht betroffen gewesen zu sein.
Auch hier geht nun wieder alles.
Was ich Cloudflare zu Gute halte ist, daß sie immer die Ursachen von großen Störungen sehr detailliert offengelegt haben: https://blog.cloudflare.com/tag/post-mortem/
Auch im o.g. X-Post wird das angekündigt – ich bleibe gespannt.
ist Online: https://blog.cloudflare.com/18-november-2025-outage/
Die Aussage des CEO von Wire finde ich sehr treffend.
Im Zuge des AI Hype gibt es noch viele Dinge, die korrigiert und justiert werden, wenn es wirtschaftlich für die Zukunft erfolgreich werden wird.
Die Hardware für die Infrastruktur und ihre Verlässlichkeit, Performance und die Lieferketten werden das auch noch zeigen.
Die Börse zeigt aktuell, das diesbezüglich die Bäume nicht in den Himmel wachsen.
Gibt es eigentlich eine Alternative für Cloudflare aus europäischem/deutschem Raum?
Gibts
https://docs.ionos.com/cloud/network-services/ddos-protect
https://docs.ionos.com/cloud/network-services/cdn
Mich wundert, siehe oben, das 1und1 das nicht selbst nutzt.
Und wenn man sich bei IONOS Hosting anmeldet, wird das Produkt als "IONOS CDN powered by Cloudflare" verkauft, nun denn…
unsere und ihre eigene Seite war auch betroffen.
Bei mir streikt der Kalendersync unter Android mit unserem Exchange.
"Wissentlich" ist da nichts bei Cloudflare…
Stand jetzt ist der Kalender weiterhin einfach verschwunden.
Mailsync wiederum funktioniert, obwohl das Protokoll ja das gleiche sein sollte.
Betrifft das noch jemanden?
Moin! Kann die Probleme ebenfalls bestätigen, jedoch findet man beim googeln, das auch Menschen ohne Tobit die gleichen Probleme haben. Auch echtes Exchange und andere.
Im David-Forum.de wurde Gmail App als Ursache vermutet, kann ich aber noch nicht bestätigen.
Bei uns ist es seit gefühlt 3 Tagen so, das immer die Kontakte aus EAS fehlten (obwohl die Sync ohne Fehler lief), wenn auch gleichzeitig Mails und Termine über EAS gesynct wurden.
Aktuell syncen wir nur die Kontakte, das funktioniert.
Nehme ich aber bsw. die Termine dazu, verschwinden die gesyncten Kontakte sofort wieder aus APP Kontakte, WhattsApp und dergleichen.
So kann man wenigstens kommunizieren, aber verpennt halt alle Termine. Riesen SCH…. Dammich.
Hatte gerade ein Update (ver. 2025.11.09.830318519….) für Gmail entdeckt, was gestern noch nicht da war und installiert, leider hat das den Fehler mit EAS nicht behoben.
Hoffe auf News von Euch, das es wieder besser wird :)
Bei mindestens 2 Fällen konnte das Problem gelöst werden, indem das Exchange-Konto gelöscht und neu hinzugefügt wurde.
Bei uns hat das leider nicht funktioniert.
Ich habe das Thema im Blog-Beitrag hier mal aufgegriffen. Scheint an der GMail-App und dem letzten Update zu hängen.
Von der dezentralen militärisch inspirierten Idee des Arpanet ist dank etlicher BigTech's echt nicht mehr viel übrig.
Cloudflare braucht eindeutig ein Cloudflare vorgeschaltet. 😉
Und was war nun der Fehler?
https://www.forbes.com/sites/kateoflahertyuk/2025/11/18/cloudflare-down-global-outage-impacting-large-parts-of-the-internet/
"The root cause of the outage was a configuration file that is automatically generated to manage threat traffic. The file grew beyond an expected size of entries and triggered a crash in the software system that handles traffic for a number of Cloudflare's services. "
Also letzten Endes: Dummheit/Nachlässigkeit
—
GB: Hier der Post-Incident-Bericht von Cloudflare Cloudflare outage on November 18, 2025
Na ja, das als "Dummheit/Nachlässigkeit" zu etikettieren ist vllt. doch etwas stumpf-eindimensional – man kann hier wohl eher maximal fehlende Weitsichtigkeit oder visionistische Vorstellungsbefähigung bemängeln, weil die Größe der Konfigdatei nicht ausreichend kapazitiv eingeschätzt wurde.
Ein typisch menschliches Versagen, weil eben durch Naturgesetzlichkeit fehlerbehaftete Menschen involviert sind! 🤷♂️
Der Originalreport beantwortet es umfangreicher
https://blog.cloudflare.com/18-november-2025-outage/
Letztendlich war es eine Art "Lieferkettenangriff" über eine externe Datenbank (ClickHouse), die bei IDENTISCHER SQL-Abfrage plötzlich ein völlig anderes Resultat brachte. Ja, die Abfrage war fehlerhaft (zu wenig eingegrenzt), aber letztendlich hat eine externe Änderung die Bombe zur Explosion gebracht.
Deswegen ist eine der wesentlichen Änderungen (die das Versprechen unterstützen sollen, das so etwas nie wieder vorkommt)
>>> Hardening ingestion of Cloudflare-generated configuration files in the same way we would for user-generated input <<>> Enabling more global kill switches for features <<<
kann man zwiespältig sehen. Ja, er hätte vermutlich die globalen Auswirkungen begrenzen können, aber er vergrößert natürlich die Angriffsfläche.
ups, da ist was zwischen den Pfeilen verloren gegangen. Ich wollte darauf hinaus, daß das ein Zero-Trust-Ansatz ist.
Allem was irgendwie mit "Zero-Trust" in Zusammenhang gebracht wird, sollte man wohl null komma null Vertrauen entgegenbringen.
Das war keine externe Änderung, Cloudflare betreibt den ClickHouse Datenbank-Cluster selber und hat etwas an den Berechtigungen geändert was zur Folge hatte das die Abfrage mehr Daten geliefert hat als das Bot-Management verarbeiten konnte. Dies konnte aber nur passieren weil im Programmcode von dem Bot-Management eine Rust unwrap(X) Anweisung benutzt wurde die explizit zur Panic führt wenn X ein Error ist.
Anscheinend dürfte Cloudflare schon wieder Probleme haben
Folgende webseiten habe ich getestet und bekomme überall folgenden Fehler
500 Internal Server Error
cloudflare
Getestet Webseiten:
https://www.linkedin.com/
https://xn--allestrungen-9ib.at/
https://allestoerungen.at/
https://web.grindr.com/
Allerdings sagst cloudflare:
Cloudflare System Status
ORD (Chicago) on 2025-12-05
In progress – Scheduled maintenance is currently in progress. We will provide updates as necessary.
Dec 05, 2025 – 07:00 UTC
Scheduled – We will be performing scheduled maintenance in ORD (Chicago) datacenter on 2025-12-05 between 07:00 and 11:00 UTC.
Traffic might be re-routed from this location, hence there is a possibility of a slight increase in latency during this maintenance window for end-users in the affected region. For PNI / CNI customers connecting with us in this location, please make sure you are expecting this traffic to fail over elsewhere during this maintenance window as network interfaces in this datacentre may become temporarily unavailable.
You can now subscribe to these notifications via Cloudflare dashboard and receive these updates directly via email, PagerDuty and webhooks (based on your plan): https://developers.cloudflare.com/notifications/notification-available/#cloudflare-status.
Dec 5, 2025 07:00-11:00 UTC
Jetzt kam noch folgendes dazu:
Cloudflare Dashboard and Cloudflare API service issues
Investigating – Cloudflare is investigating issues with Cloudflare Dashboard and related APIs.
Customers using the Dashboard / Cloudflare APIs are impacted as requests might fail and/or errors may be displayed.
Dec 05, 2025 – 08:56 UTC
aber da sollten doch theoretisch die Webseiten ja trotzdem gehen oder?
Ist im Blog Cloudflare-Störung(5.12.2025)
https://www.deskmodder.de/blog/2025/12/05/cloudflare-stoerung-500-internal-server-error-legt-zahlreiche-dienste-lahm/