
 [English]Kurze Frage in die Runde: Gibt es bei euch aktuell (20.10.2025, ab 9:30 Uhr) Störungen bei Amazon (oder AWS-Diensten) und beim Messenger-Dienst Signal? Mir ist gerade ein Leserhinweis auf Störungen zugegangen. Ein erster Test zeigte keine Probleme, aber bei genauerem Hinsehen konnte ich verifizieren, dass bei Signal ein Problem vorliegen muss. Auch allestoerungen.de zeigt, dass Leute Störungsmeldungen absetzen und etwas zu passieren scheint. Hier einige Informationen.
[English]Kurze Frage in die Runde: Gibt es bei euch aktuell (20.10.2025, ab 9:30 Uhr) Störungen bei Amazon (oder AWS-Diensten) und beim Messenger-Dienst Signal? Mir ist gerade ein Leserhinweis auf Störungen zugegangen. Ein erster Test zeigte keine Probleme, aber bei genauerem Hinsehen konnte ich verifizieren, dass bei Signal ein Problem vorliegen muss. Auch allestoerungen.de zeigt, dass Leute Störungsmeldungen absetzen und etwas zu passieren scheint. Hier einige Informationen.
Admin-Passwörter schützen mit Windows LAPS. eBook jetzt herunterladen » (Anzeige)
Ergänzung: Ist ein Beitrag "in Progress". Inzwischen ist klar, in USA sind AWS-Server gestört und das "halbe Internet" ist tot – selbst lokale Autodesk-Installationen mucken wegen fehlendem Lizenz-Server. Single Point of Failure – und US-Server kicken europäische Nutzer, deren Daten nur in Europa in der Cloud gehostet werden, aus den Diensten raus. Konnte ja keiner ahnen, die Prospekte sahen so gut aus und versprachen gar viel.
Gegen 12:00 Uhr deutscher Zeit scheinen die Dienste langsam wieder zu kommen. AWS gibt auf der Statusseite an, dass man das Problem behoben habe.
Ein Leserhinweis
Ein Blog-Leser hat mich gerade per E-Mail mit dem Betreff "Amazon down?" kontaktiert und mich über Probleme informiert. Er schrieb, dass Signal bei ihm definitiv nicht funktioniert, es gingen keine Nachrichten raus. Aber auch so klemme es. Er vermutet, dass das Problem bei AWS liegt.
Signal hat Probleme
Die Signal-Statusseite behauptet zwar, alles wäre funktional. Ich habe dann gegen 9:36 Uhr versucht, eine Nachricht per Signal zu verschicken. Die wurde zwar "scheinbar" verschickt. Am Smartphone des Empfängers kam aber nichts an – sondern ich wurde informiert, dass "möglicherweise Nachrichten vorliegen".
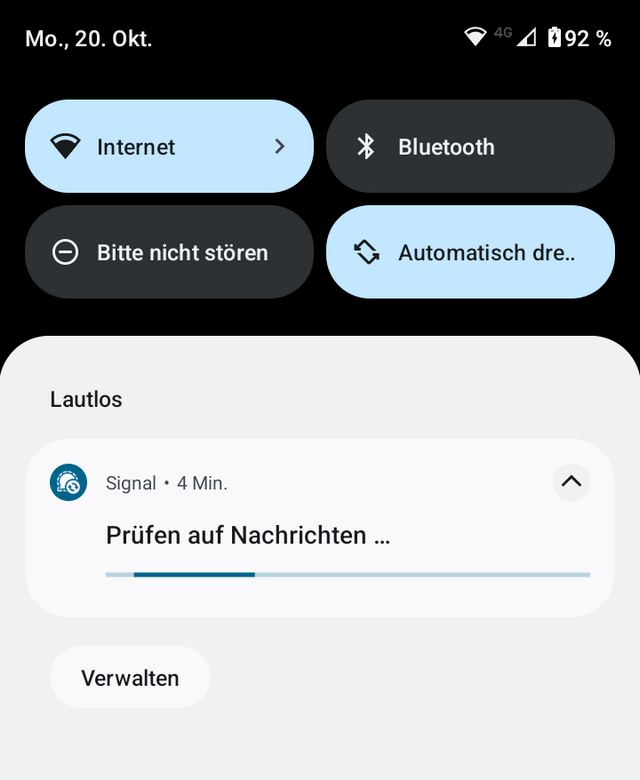
Beim Versuch, die Signal-Nachrichten abzurufen, bleibt das Smartphone in obiger Fortschrittsanzeige hängen und bekommt nichts ausgeliefert.
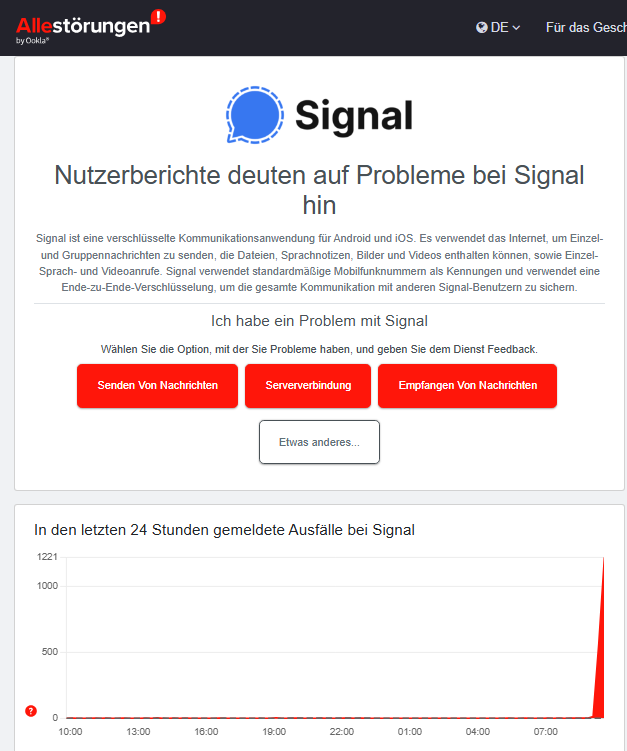
Auf der Plattform allestoerungen.de zeigt sich, dass es ab ca. 9:00 Uhr zu Problemen gekommen zu sein scheint – über 1200 Meldungen pro Zeiteinheit signalisieren, dass einige Leute betroffen sind. Gut 66 % der Nutzer beklagen, keine Nachrichten versenden zu können. Bei 7 % der Störungsmelder werden keine Signal-Nachrichten empfangen und 27 % der Nutzer melden Probleme mit der Server-Verbindung.
Breite weltweite Störung
Ich habe dann schnell auf X nachgeschaut, was es dort zu vermelden gebe. m4rio bemängelt ebenfalls, dass die Signal-Statusseite keine Störung anzeige, aber er bekommt die Meldung, dass die Netzwerkverbindung gestört sei und er diese prüfen müsse.
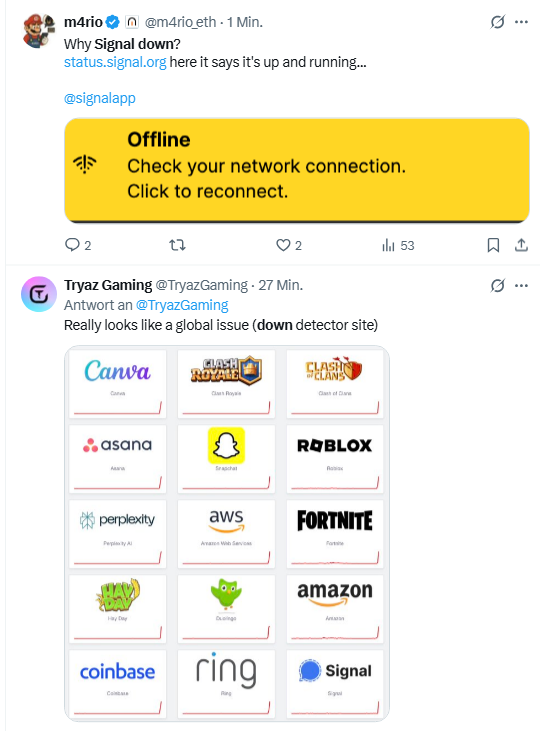
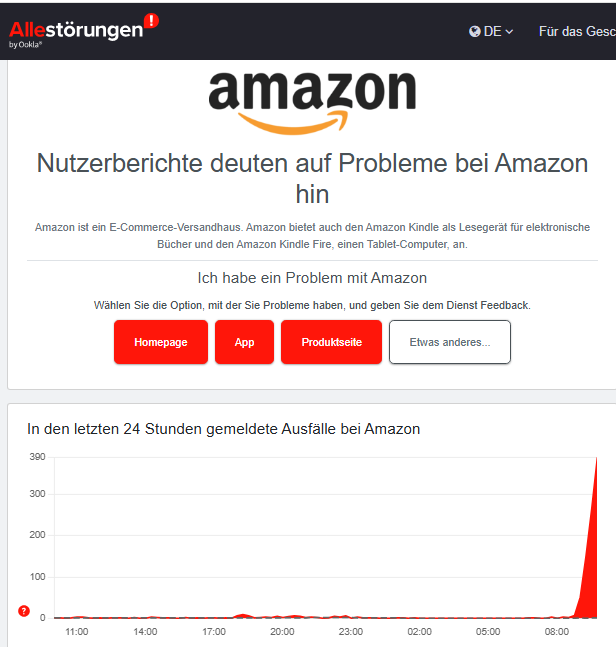
Im zweiten, im Screenshot erfassten Tweet hat Tryaz Gaming einen Übersicht gepostet, die zeigt, dass sehr viele Dienste gerade in eine Störung laufen. Dazu gehört auch Amazon. Auf allestoerungen.de findet sich eine Bestätigung.
Inzwischen kristallisiert sich heraus, dass es eine größere AWS-Störung in den USA gibt. Auf der AWS-Statusseite heißt es inzwischen:
Oct 20 12:11 AM PDT We are investigating increased error rates and latencies for multiple AWS services in the US-EAST-1 Region. We will provide another update in the next 30-45 minutes.
Und dann wurde das folgende Update unter "Operational issue – Multiple services (N. Virginia)" gepostet:
Increased Error Rates and Latencies
Oct 20 12:51 AM PDT We can confirm increased error rates and latencies for multiple AWS Services in the US-EAST-1 Region. This issue may also be affecting Case Creation through the AWS Support Center or the Support API. We are actively engaged and working to both mitigate the issue and understand root cause. We will provide an update in 45 minutes, or sooner if we have additional information to share
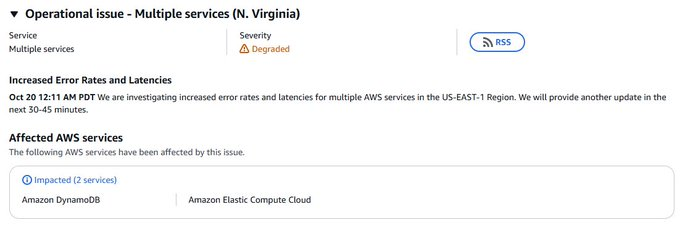
Betroffen sei der Dienst Amazon DynamoDB heißt es, und viele weitere AWS-Dienste sind dadurch beeinflusst. Und mit der AWS-Störung fallen weitere Dienste aus, die auf AWS aufsetzen. Betroffen sind Amazon, Xbox, Roblox, Snapchat, Playstation Network(PSN), EPIC Games und viele andere Dienste. Der Fall zeigt erneut die Abhängigkeiten in der IT auf.
Autodesk-Anwender leiden
Es kommt in den nachfolgenden Kommentaren bereits zur Sprache: Nutzer von Autodesk sind wohl auch betroffen. Gerade hat sich ein Leser gemeldet und meinte "Muss ja nicht immer Windows schlimm sein, uns plagen aktuell Autodesk Ausfälle, und die Zahl der ausgefallenen Service steigt seit 10 Uhr rapide an." Ich habe ihn auf den Beitrag hier verwiesen, damit klar ist, auf welch "schwankendem Schiff" unsere moderne Software-Infrastruktur aufgebaut wurde.
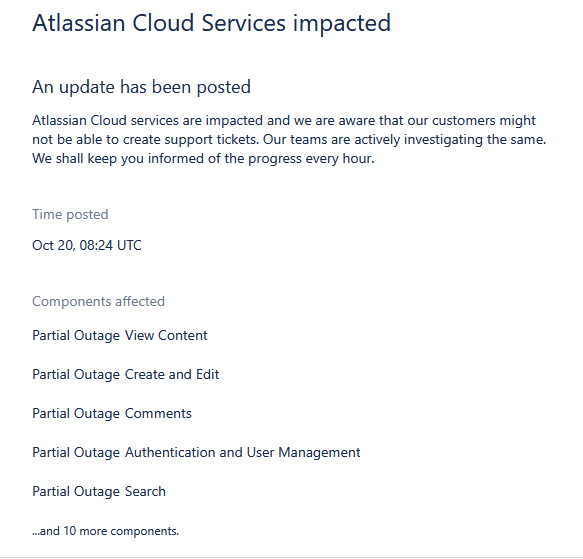
Auch Atlassian betroffen
Leser haben mich darauf hingewiesen, dass die Dienste von Atlassian – samt Ticket-System – betroffen sind. Ein Leser hat mir folgendes dazu geschickt (danke).
Die gematik TI hat ebenfalls Schluckauf
So langsam wird das ganze Desaster sichtbar, was ein "Single Point of Failure" und ein Rechenzentrums-Problem in Virginia USA auslösen kann. Europäische Nutzer werden ja – laut Prospekt – in Europa gehostet und deren Daten bleiben auch dort. Nun informiert ein Nutzer in den nachfolgenden Kommentaren, dass die Technische Infrastruktur (TI) der gematik für eRezept, ePS, VDSM just im Moment Probleme habe.
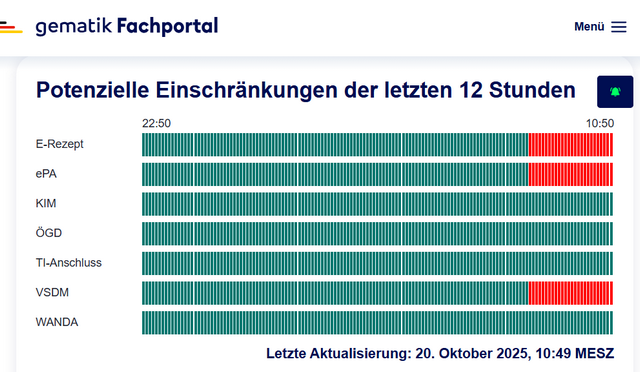
Ich habe mal einen Screenshot des gematik Fachportals mit den TI-Störungsanzeigen gemacht. Es heißt dazu, dass es aktuell es zu Einschränkungen bei der Nutzung des Versichertenstammdatenmanagements (VSDM) und damit beim Einlesen von elektronischen Gesundheitskarten (eGK) kommen kann.
Betroffen sind Versicherte u. a. BERGISCHE Krankenkasse, Bertelsmann BKK, BKK Diakonie, BKK DürkoppAdler, BKK exklusiv, BKK firmus, BKK Freudenberg, BKK GILDEMEISTER SEIDENSTICKER, BKK HERKULES, BKK KARL MAYER, bkk melitta hmr, BKK Merck, BKK Pfalz, BKK ProVita, BKK Public, BKK Salzgitter, BKK Technoform, BKK Werra-Meissner, BKK24, Continentale BKK, energie-BKK, Heimat Krankenkasse, mhplus Krankenkasse, pronova BKK, SECURVITA Krankenkasse, Südzucker-BKK, TUI BKK, vivida bkK und die Bundespolizei.
Die Störung kann Auswirkungen auf die Nutzung der elektronischen Patientenakte (ePA) und das Einlösen von E-Rezepten mittels eGK haben, andere Einlösewege sind nicht betroffen.
Ergänzung: Die Störungen der TI begannen mit den AWS-Störungen und waren behoben, nachdem auch AWS und die anderen Dienste wieder liefen – ein Schelm, wer da drüber nachdenkt, dass die eRezept- und ePA-Daten von AWS-Diensten abhängigen.








Ja, habe dieselbe Meldung auf Signal "Checking for messages"…
Es knirscht gerade mächtig im Gebälk. Abwarten…
Wer die überladene us-east-1 als Instanz nutzt ist selbst schuld. Überladen im Sinne von Kunden, nicht von services. Das vergeigen ist jedenfalls aromatisch, es war angeblich nur DNS:
https://i.postimg.cc/9Q24PnYt/are-we-down-yet.png
Anscheinend ist aktuelle das Lizenzsystem von Autodesk (AutoCAD) auch down. Man kann sich anmelden, aber unter "Produkte" kommt nur eine weiße Seite und alle lokalen Rechner beschweren sich über fehlende Lizenz.
Hab hierzu heute auch ein paar Tickets bekommen.
Somit sind leider die lokalen (!) Autodesk Produkte teilweise nicht nutzbar. Großes Kino…
Dieses Problem kann ich bestätigen. Seit ca. 9:00 Uhr sind keine Logins bei Autodesk mehr möglich. Und wenn der Login möglich ist, ist die Lizenz nicht verfügbar. Das Unternehmensportal lädt auch nicht.
Die gleiche Situation bei uns. Alle, die sich heute früh angemeldet haben, wurden registriert. Ab ca. 10 Uhr wurde die Lizenz-Anmeldung mit einem Fehler quittiert. Autodesk scheint eindeutig dabei zu sein.
Bei mir genau das selbe. Ich komme nicht mal mehr in meinen Autodesk Account.
Meine Mail existiert angeblich nicht….Oder es kommt ein Interner Server Error.
Bei uns genauso.
Seit ca. 10:00 wird mit Autodesk Produkten (AutoCAD und Inventor immer schlimmer. War das noch gut als wir die Lizenzen intern verwalten konnten.
Wie jetzt? Gibt es keine lokalen Lizenzserver mehr?
Nein – leider nicht mehr. Die wurden zwangsweise von Autodesk gestoppt und nun auf die Cloud Lösung welche ja sooooo stabil läuft umgeswitcht. ;-)
Bei Autodesk nicht mehr. Das Ganze läuft inzwischen komplett auf dem Online Dienst von Autodesk, eine lokale Instanz ist nicht mehr vorgesehen. Das aber auch schon seit ein paar Jahren. Wir hatten früher Gerätebasierte Lizenzen für PowerMill, bei einer Verlängerung wurden wir dann gezwungen auf Benutzerbasierte Online Lizenz umzustellen.
Lernen durch Schmerzen.
Zoom funktioniert gerade auch nicht…beim Starten einer Videokonferenz erscheint ein Fehler. Auch Perplexity AI funktioniert nicht vollumfänglich.
Da laut allestörungen.de auch viele Probleme mit AWS gemeldet werden, liegt der Verdacht nahe, dass die Amazon Web Services ein Problem haben..
Kann ich nur bestätigen. Auch mit der Zensurumgehung auf zwei Endpunkten funktioniert es nicht……mache mir Sorgen. Signal ist sehr wichtig für mich…
Steam und EA ebenfalls davon betroffen…
Allgemein fast alles gerade. Telegram läuft noch, WhatsApp so halb (aber das hat in den letzten Wochen sowieso dauernd Aussetzer), Spotify geht auch noch. YouTube hat eben angefangen Probleme zu machen, und da zweifle ich dran dass die ihre Sachen bei Amazon liegen haben. Und alles an Social Media zeigt auch rote Graphen.
Eventuell wieder ein großer DNS-Ausfall, wie wir ihn vor einem halben Jahr schon mal hatten?
Hier nur 1 Häkchen: also Message ist raus aber nicht angekommen.
Wir haben aktuell Probleme mit Autodesk. Kommen nicht über die Website in denn Account und ein Client kann sich deswegen wohl keine Lizenz ziehen.
Ja – bei uns leider genau so. Fliegen immer mehr raus aus AutoCAD und Inventor.
Autodesk ist ebenfalls betroffen / eingeschränkt
https://health.autodesk.com/
Caseware selbiges. Ausfall durch AWS.
HPE Instant On Geräte ebenfalls.
https://status.atlassian.com/
Ist auch kaputt, die hosten bekanntlich alles bei aws
Auch bei uns ist ein System gestört. Ein Mitarbeiter wollte sich in einem Chat Client anmelden bekommt aber kein one time password. Glück hat wer noch eingeloggt ist.
…was lernen wir daraus? Es ist nicht unbedingt geschickt, wenige grosse Anbieter von Webservices zu haben, denn wenn es bei denen mal hakt, fällt gleich viel aus.
Bei mir (Schweiz) verbindet sich Signal auch nicht (Netzverbindungsfehler von oben), aber alle meine lokalen Dienste und auch die bei meinem (Schweizer) Webhoster Cyon laufen zuverlässig.
Da ich selber nichts bei AWS oder anderen Cloudanbietern habe, sondern auf meinen eigenen Servern, kann ich meine Arbeit ganz normal durchführen :-).
Bei mir meinte ein Leser in einer privaten Nachricht auf Facbook "Es gibt aktuell einen großen Ausfall bei united domains.., vielleicht interessant für dich" und gab an, dass einige Kunden von ihm betroffen seien. Die Seite allestoerungen.de zeigt so 40 Meldungen pro Zeiteinheit für united domains (Domain Registrar).
Besonders spannend:
Laut AWS status page gibt es Probleme "nur" in US-EAST-1.
Betroffen sind aber auch andere Dienste (z.B. Atlassian), die angeblich für EU Kunden in EU gehosted sind…?
War da nicht mal was mit "availability zones" und "availability" zu erhöhen…?
Interessanter Gedanke – ob die jetzt mit heruntergelassener Hose erwischt wurden und man feststellt: "Oh, hinten rum sind die total blank"?
Laut reddit posts werden wohl einige zentrale Dienste wie IAM (vorranging?) in US-EAST-1 gehostet, bzw. sind davon abhängig.
Ein on-prem Klassiker, aber bei AWS doch etwas enttäuschend.
Aruba Instant On ist auch Offline.
Das Admin Center von Withsecure Elements ist auch betroffen:
https://status.withsecure.com/
Sowie ein paar Dienste von ZScaler:
https://trust.zscaler.com/zscaler.net/incidents
Und auch Cloudflare:
https://www.cloudflarestatus.com/
Hier ebenfalls Signal gestört. Hatte heute komischerweise auch einen Fail bei einer Synology Replikation von ABB Backups. Kam bisher noch nie vor. Aktuell schwierig zu sagen ob's damit zusammenhängen könnte (ABB Package muss ja auch online aktiviert werden). Kann auch eine zeitliche Koinzidenz sein.
Ja, Signal läuft nicht (10:35). Nutze die F-Droid-Version.
Störung scheint behoben. Signal ist wieder online.
Und da kippen sie alle, die mit den tollen Cloud-First-Strategien. Und auch jene die einem immer sagen, aber wir haben Multicloud… ich würd' sagen läuft!
Bitre gerne mehr davon…
Worin siehst du genau den Unterschied zu früher, als alles in einem Rechenzentrum stand oder auf einem Server Inhouse gehostet wurde? Worin genau liegt beim Thema "Ausfallssicherheit" der Rückschritt? Ich rede hier bewusst nicht von selbst konstruierten Abhängigkeiten, sondern nur von Ausfallssicherheit.
Ich denke nur Redundanz kann dir hier helfen – auf allen Ebenen. Das müsste dann konsequent auch bedeuten, dass man z.B. nicht nur einen Virtualisierungshersteller nutzt (siehe VMware Debakel), dass Netzanbindungen und Strukturen redundant sind.
Falls du in der IT arbeitest, kennst du ja die Antwort von der Führungsetage dazu schon…
Naja es ist etwas anderes wenn meine Systeme stehen, weil ich Bockmist gebaut habe, oder meine Systeme stehen weil ander Bockmist bauen!
;-P
Aber ja ist nen leidiges Thema… nur hab ich da keinerlei Mitleid!
You get what you paid for!
Die TI nutzt viel bei AWS, Azure und Google Cloud.
Es stand eben nicht *alles* in *einem* Rechenzentrum…
Es ist immer eine Frage der Abwägung und des Preises.
https://blog.jakobs.systems/blog/20250820-it-erfolg-messen/
P.S. Viele Geschäftsführer können nicht rechnen…
In der TI scheinen dadurch auch ein paar Dienste betroffen zu sein.
https://fachportal.gematik.de/ti-status
Signal (10:45): Niht verbunden Überprüfe deine Netzwerkverbindung. …
Cloudflare macht weltweit Wartung. D'dorf so:
"We will be performing scheduled maintenance in DUS (Düsseldorf) datacenter on 2025-10-20 between 08:00 and 17:00 UTC."
https://www.cloudflarestatus.com/incidents/nr5657fm4jys
Trend Micro teilweise auch: https://status.trendmicro.com/en-US/
Docker ist down.
https://www.dockerstatus.com/pages/incident/533c6539221ae15e3f000031/68f5e1c741c825463df7486c
Pulls gehen immer noch nicht durch, selbst nach Login für public Repos.
Stand: 13:52 Uhr
Unsere Autodesk Lizenzen schmieren auch eine nach der anderen ab. Komme auch nicht mehr auf das Lizenz-Verwaltungs Tool
Der Epic Games Store hat grad ebenfalls Probleme:
https://xn--allestrungen-9ib.de/stoerung/epic-games-store/
Eine kurze Recherche gab, dass die ebenfalls bei Amazon gehostet werden:
https://aws.amazon.com/de/solutions/case-studies/innovators/epic-games/
Bei mir funktioniert gerade der Login nicht.
Bei mir läuft Amazon Music nicht. Es geht nur das Fenster auf, aber darin ist dann nichts.
Nachtrag 11:27 Uhr: Es geht wieder. Scheint wieder auf die Beine zu kommen.
Katastophen, jemand weinte, weil die Ring-Kameras nicht gehen, Alexa bleibt stumm …
Ich empfehle Radio Caroline auf 648kHz, ist unabhängig von diesem neumodischen Internet ;-)
Wir nutzen https://www.nasuni.com/ für unsere Filedienste. Hier hakt es im Moment auch etwas. Auch hier wurde vom Support auf die AWS Störung verwiesen.
Ich habe mich mit dem Dienst noch nicht beschäftigt. Mir ist aber der Claim "Hybrid Cloud" aufgefallen. Was genau bedeutet "Hybrid" bei denen, wenn ein AWS Ausfall den Dienst runter zieht?
Der Dienst an und für sich war noch verfügbar und die User haben nichts mitbekommen.
Kurz zusammen gefasst… das ganze funktioniert ja so, dass man einen lokalen Cache hat, gegen den sich die User verbinden und im Hintergrund verbindet diese Cache Appliance gegen einem Cloud Storage. Also die Cache Appliance verbindet gegen einen S3 deiner Wahl und legt dort verschlüsselt seine Daten ab. Der User spricht aber immer nur lokal gegen die Appliance und merkt gar nicht das Cloud Storage genutzt wird.
Scheinbar hat Nasuni Teile seiner Infrastruktur für Managment bei AWS liegen was zu den Störungen geführt hat. Es gibt da zum Beispiel Dienste wie "global file lock". Also wenn über unterscheidliche Cache Appliances die gleiche Datei geöffnet wird, muss Appliance A ja irgendwo her erfahren das Appliance B diese Datei geöffnet hat und das scheint wohl über AWS zu laufen.
Messenger -> DeltaChat
SocialMedia -> Fediverse
nix Zentrales 😃
Das Trendmicro Vision one Portal zeigt eine "Urgent Maintenance in Progress" an, hängt vermutlich auch mit dem zusammen. Auch im Exchange online Admin Center werden keine Mailboxen angezeigt, bzw. das Portal öffnet sich aktuell nicht mehr.
Der folgende Befehl liefert keine "Internet Address"-IPv4 (A) für EAST-1:
nslookup -debug dynamodb.us-east-1.amazonaws.com 1.1.1.1
Hingegen der folgende Befehl für EAST-2 liefert eine "Internet Address"-IP:
nslookup -debug dynamodb.us-east-2.amazonaws.com 1.1.1.1
Beim zweiten Befehl liegt der DNS-Server für IPv6 (AAAA) in UK (England), beim ersten in den USA.
Die IP für EAST-1 (dynamodb. us-east-1. amazonaws. com) sollte sein
3.218.182.212
Diese Adresse ist pingbar.
Der folgende Befehl bei einer Zuordnung von URL und IP meldet "healthy" und "connection[…] intact":
curl -v –resolve "dynamodb. us-east-1. amazonaws. com:443:3.218.182.212" *ttps: // dynamodb. us-east-1. amazonaws. com/
Daraus schließe ich, der EAST-1-Server für DynamoDB ist noch da, aber der zuständige DNS-Server übersetzt die URL nicht in eine IP-Adresse.
Edit (11:15 Uhr):
Der erste Befehl liefert jetzt wieder eine "Internet Address"-IPv4, aber eine andere:
3.218.180.157
statt
3.218.182.212
Switch auf Ersatz-Server für DyanmoDB und Änderung im DNS-Server.
Super Beitrag.
Bitte aber an den FQDN nuch ein "." anhängen. Sonst packt der Client noch sein DNS Suffix dran.
Dann ist bei dir diese Option in den Netzerkadapter-Einstellungen eingeschaltet:
learn. microsoft. com/en-us/answers/questions/1477710/why-windows-11-add-a-dns-suffix-to-fqdn
Schalte sie aus, dann braucht man keinen Punkt.
Bei Windows 10 ist die Option aus,
bei Windows 11 ist die Option an.
Mitten in der Produktion steigt Autocad aus, Katastrophe
Ich nehme an, der Mietvertrag ist entsprechend geregelt, dass man von Autodesk Schadensersatz bekommt?
Wovon träumst du? Als wenn Softwarehersteller/Lieferanten jemals für irgendwas gerade stehen mussten.
Was lernt ihr daraus? Was ändert ihr?
Der Kunde muss gar nichts ändern. Ich sehe da den Software-Hersteller in der Pflicht. Die Nutzung verweigern, nur weil der Lizenz-Server mal für ein paar Minuten nicht erreichbar ist?! Absolut lächerlich.
Aber was willst du als Kunde tun? Ein Zeichen zu setzen und auf ein Konkurrenzprodukt umzusteigen wird nahezu unmöglich sein – Autodesk ist ein Platzhirsch wie Adobe: Du kannst zwar Alternativen nutzen, aber nicht ohne eine Menge Kompromisse eingehen zu müssen.
Atlassian ist wohl auch betroffen.
https://confluence.status.atlassian.com/incidents/5k4nczw5q2jy
Info von 11:25:
"We are experiencing an outage due to some issue at the end of our public cloud provider."
Vermutlich nutzen die auch AWS.
Danke, siehe auch die obige Ergänzung im Text.
Bei Autocad ist auch ein Windowsupdate (KB5066835) schuld, wenn man sich nicht anmelden kann.
Nutzt man dieses Tool, funktioniert es wieder:
https://download.microsoft.com/download/16d61dc0-7e94-4cd2-ba3c-4f59dece8488/Windows%2011%2024H2,%20Windows%2011%2025H2%20and%20Windows%20Server%202025%20KB5066835%20251015_22001%20Known%20Issue%20Rollback.msi
Ich hab es jetzt 2 Stunden lang probiert, Autocad wieder zum laufen zu kriegen, aber jedes mal bricht der Anmeldeprozess mit einer Fehlermeldung ab. Mit dem Tool hat es endlich wieder funktioniert und die Mitarbeiter konnten sich anmelden.
Der Fehler ist behoben:
"Oct 20 2:27 AM PDT We are seeing significant signs of recovery. Most requests should now be succeeding."
health. aws.amazon. com/health/status
Der Fehler mag behoben sein, jetzt müssen "nur" 600 Milliarden Events von über 3 Stunden in die DynamoDB von allen Kunden… die Zahl mag noch zu niedrig sein. Da ist weit und breit keine Erholung in Sicht.
Also Autodesk läuft noch nicht wieder rund – keine stabile Anmeldung im Profil möglich, keine Arbeitsplätze mit Revit nutzbar, da keine Lizenz zugeteilt wird.
Signal funktioniert bei mir (Schweiz) wieder.
Hab meine Infrastruktur ebenfalls lokal mit allen nötigen Diensten, Datenbanken und Hyperweisern. Betreibe auch meinen eigenen Chat Client Service über Portainer. Ich investiere jedoch täglich mind 2 Std. für Pflege. Nicht jeder möchte so einen Aufwand betreiben….
Und wie hast du die Redundanz für den Ernstfall gelöst? Selbst hosten bedeutet ja nicht Ausfallssicherheit (so gerne ich auch Dienst selbst hoste ;-) ).
> Und wie hast du die Redundanz für den Ernstfall gelöst? Selbst hosten bedeutet ja nicht Ausfallssicherheit
OnPremise an getrennten Standorten bedeutet schon Redundanz / Ausfallsicherheit. Kostet halt nur mehr.
Unsere kritische Infrastruktur ist redundant und ausfallsicher aufgebaut.
Weniger kritische Infrastruktur / Anwendungen können halt auch mal nicht verfügbar sein.
Bei uns im Büro liefen von 9.00 – 11.45 Uhr drei Autodesk CAD-Programme nicht mehr wegen Lizensierungsfehlern. Acht andere Autodesk-Produkte waren nicht betroffen, bzw. liefen glücklicherweise weiter….schon verrückt, wie das Ganze verflochten ist.
Eigentlich müssten jetzt alle Büros Autodesk auf Arbeitsausfall verklagen, damit die Lizensierung in Zukunft stabiler aufgesetzt wird…
Was lernt ihr daraus? Was ändert ihr?
Wirst schlechte Karten haben.
Ich hab die AGB von Autodesk nicht im Kopf, aber die werden wie jeder Cloud-Anbieter eine Verfügbarkeit von 99,X Prozent gewährleisten.
Wenn du das auf aufs ganze Jahr hoch rechnest, also 8766 Stunden, sind ein Ausfall von ~4 Stunden im Jahr noch lange kein Grund zu Klagen.
Muss man halt wissen wenn man sich auf sowas einlässt…
Danke für den Hinweis – ja, sowas wird da drin stehen…wie bei den Internet-Providern.
Wir selber können an der Thematik nichts ändern, außer unserem AutoDesk-Anbieter darauf hinzuweisen, das uns solche Totalsausfälle weh tun und nicht mehr vorkommen sollten. Einen eigenen Lizenzserver zu betreiben macht für unser kleines Büro keinen Sinn.
Da CAD-Software im Allgemeinen und AutoDesk – Produkte im Besonderen, recht kostenintensiv sind, und damit eigentlich genügend finanzielle Ressourcen im System sein müssten, besteht vielleicht die Möglichkeit, das AutoDesk Konsequenzen aus dem Vorfall zieht und solche essentiellen Dienste wie die Lizensierung künftig robuster macht…
meetup(dot)com Seite geht hier gar nicht mehr.
Wir sind auch, zumindest was die Lizenzvergabe bei Autodesk angeht, wieder handlungsfähig. Der Profilzugriff stockt noch ein wenig.
wow, das mit den Lizenzproblemen ist übel. Können die lokal installierten Programme nicht 2-3 Tage die Lizenzgültigkeit puffern bzw. 2-3 Karenztage einräumen, bis ggf. die Updateserver wieder laufen? Technisch sicher kein Problem. Hat nur kein Programmierer dran gedacht oder der Produktmanager hat in der Besprechung abgewunken ("Für solche seltenen Fälle programmieren wir nichts auf unsere Kosten…").
Du hast leider pech wenn Du genau an einem Tag wie heute betroffen bist. Da machste nix :(
Quelle: https://www.autodesk.com/support/technical/article/caas/sfdcarticles/sfdcarticles/How-to-work-offline-on-autocad-lt.html
[…] However, you need to connect to the Internet every 30 days to verify that your subscription is still current [/…]
Emm. Auch wenn sie nur alle 30 Tage die Lizenz testen, wäre natürlich eine Karrenz von einer Woche oder gar nochmal 30 Tagen möglich.
ja. das ist natürlich deutlich aufwändiger zu programmieren als nur if heute keine Lizenz, dann war es für heute und den Rest mit arbeiten.
ja, natürlich könnten ein paar Kunden so nochmal 30 Tage raus schinden und sie können nicht sofort wirksam durch abgeklemmen genötigt werden, wenn sie mal nicht pünktlich zahlen. Aber wozu haben wir dann noch Gerichte? Hallo?
Selbstjustiz?
Vermutlich hat niemand gefragt was passiert…
in 30 Tagen Karrenz kann man schon ein neues Kabel legen, aber das eine seriöse Weltfirma wie Autodesk so stupide programmiert haben soll kann ich mir nicht vorstellen.
Die wissen doch, das der Ausfall des Lizenz Servers dem Kunden zig Tausende kostet, aber dass "regelmäßig" ein Bagger ein Kabel umverlegt oder ein Terrorist sogar eine redundante Ring Verkabelung an 2 kritischen Stellen kappen kann.
irgendwas stimmt an der Story nicht
In dem Fall war vermutlich das Problem, dass der Rechner grundsätzlich Internet hatte und auch die Login Server von Autodesk erreicht hat.
Dann sind aus unserer Sicht die lokalen Lizenzen sofort ungültig geworden, außer Inventor/AutoCAD wurde bereits vor dem Ausfall gestartet.
Bei uns traf es gestern mehrere Rechner, die am Freitag zuvor noch Autodesk Produkte genutzt haben.
Es ist klar warum Autodesk das so umgesetzt hat. Wenn ich jemanden im Portal die Lizenz entziehe, dann kann er direkt beim nächsten Start das Produkt nicht mehr verwenden, außer er ist wirklich komplett offline.
In dem Fall ist es halt Mist, wenn Autodesk.com zwar noch erreicht wird, aber nicht die Meldung bringt "du hast noch eine Lizenz"…
Trend Micro ist für uns wieder erreichbar.
Was lernt ihr daraus? Was ändert ihr?
Für uns war "nur" das TM Kunden-Verwaltungsportal betroffen. Das Trend Micro E-Mail Security System hatte keine Störung, auch dessen Verwaltungsportal nicht.
Ich habe unserem technischen Kontakt bei Trend Micro empfohlen, intern die Frage zu stellen, ob TM dies nicht zum Anlass nehmen sollte, sich von der AWS Abhängigkeit zu lösen. ;-)
Wenn die gematik/TI-Störungen (u.a. ePa) heute nicht zufällig zeitgleich zu den AWS-Störungen passierte, dann würde das bedeuten, dass zumindest manche epa-relevante Funktionen auf Cloudservern eines US-Anbieters … (egal wo die stehen mögen, DSGVO-sicherer Standort in EU … bla ba) ? Nö. Wo denke ich hin. Niemals. Nein, doch, oh? :-)
Tja, der Ausfall zeigt, wie die TI mit AWS verwoben ist. Kaum läuft AWS wieder, wird auch das gematik Fachportal bei der TI wieder "grün". Obwohl: Es heißt ja, alles ist sicher, alles läuft auf deutschen, europäischen Servern – die gematik-Seiten und Karl Lauterbach haben es jedenfalls so kommuniziert …
Schönes Beispiel von "sich in die Tasche lügen"… passieren wird nichts, es geht einfach weiter.
Jop, das ist ja der Witz in Dosen^^ mit digitaler Souveränität hat das alles mal so überhaupt nichts zu tun, schau dir zum Spaß doch mal den D-Stack an und die aktuelle Kommentare, kauf dir aber vorher bisl Popcorn, du wirst es brauchen.
https://technologie.deutschland-stack.gov.de/
https://gitlab.opencode.de/dstack/d-stack-home/-/issues/?sort=created_date&state=opened&first_page_size=100
Sehe ich auch so. Seit Jahren steht ein Politiker auf und spricht "Wir müssen unsere IT souverän machen" …. und jüngst im September 2024 wird die SoftwareAG zerschlagen und der Investor ("es wird keine Zerschlagung geben") verkauft die Adabas-DBMS-Sparte an IBM. Medienecho? Keines.
Möchte nicht wissen, wieviele europ Großbetriebe noch Adabas am laufen haben (Banken, Versicherungen, Universitäten, Krankenhäuser etc).
Ich betreibe hier daher künftig meinen eigenen D-Stack … alles von US-Konzernen aber meine Maus ist ne alte von Siemens. :-)
Ich glaub denen sogar, dass das auf Servern in Europa läuft, schließlich hat AWS ja weltweit welche und von der Latenz bietet es sich an, möglichst lokale Standorte zu verwenden. Löst nur halt nicht das DSGVO-Problem mit dem amerikanischen CLOUD-Act und hilft auch nicht, wenn zentrale Steuerdienste von AWS auf die Server in USA angewiesen sind und die wie hier ausfallen. Aber der Standort kann schon Europa/Deutschland sein.
Und was lernen wir daraus: Bei der Cloud spielt der Standort nicht unbedingt eine Rolle, es kann trotzdem alles zusammen brechen.
Wenn evtl. die Daten auf Servern der EU liegen, aber die Anmeldung/Validierung beim Verbindungsaufbau evtl. über nicht erreichbare Server in den USA liefe, dann sind Daten auf EU-Servern auch nicht zugängig.
Es hieß "Datenschätze zu heben" und für diesen Zweck hat man sich die pflichtbewusst die besten Dienstleister herausgepickt :)
Diesem Lügenbold mit seinem verlogenen Aussagen
> alles ist sicher, alles läuft auf deutschen, europäischen Server
habe ich von Anfang nicht geglaubt und vertraut. Eigentlich müsste er wegen Falschaussage und Lüge verklagt und verurteilt werden!
Wenn wir dafür all unsere Politiker belangen würden, hätten wir keine mehr da sie alle im Gefängnis verrotten würden…
Es gibt da keine Straftat die da noch nicht begangen wurde! Fallschausage Lüge Urkundenfälschung sind da noch die harmlosen Fälle.
und mit der Kommunikation mit der Krankenkasse wird das auch nichts mehr, da die die die Login Dienste von Bitmark für ePA und ihr eigenes Kunden Portal nutzen.
So muss der Kunde keine aufwändige Anmeldprocedur machen und hat für beides nur ein Passwort… wie praktisch.
In mittelfristiger Zukunft wird jeder digitale Zugang sowieso alternativlos auf BundID bzw. EUid migriert.
Was Positives: Meine Nextcloud-Instanzen laufen ;-).
Auch der Blog hier läuft …
Der VW-Käfer unter den Blogs! 👍
Meine onPrem laufen auch alle und auch mein Haus ist weiterhin smart und On ;-P
zeitgleich mit der AWS Störung gibt es heute bei mir und bei bekannten einen Vodafone DSL Komplettausfall
hat auch was gutes, habe seither keine einzige blöde junkmail bekommen ;-)
Nach Aussage von NinjaOne nutzen die auch AWS. Da wir auch NinjaOne im Einsatz haben, hatte ich das heute im Blick, jedoch keinen Ausfall bemerken können.
Das ist nun mal so, wenn zentrale Dienste die "Cloud" benötigen. Da mittlerweile Lizenzdienste vieler Softwareanbieter in Clouds gehostet werden, und ein on-Prem Lizenzserver sich hiermit verbinden muss… Ich denke nicht, dass sich daran etwas ändern wird. Ausfälle wird es immer mal wieder geben.
Wenn das dreimal am Tag an zwei Tagen die Woche für mehrere Stunden vorkommt, ändert sich das ganz schnell! Wenn es mal richtig kracht und die Autodesk Lizenzserver gleich mal mehrere Tage am Stück wegbrechen und sich das in kurzer Zeit wiederholt ändert sich das auch sehr schnell.
Hier sehe ich das wie Thomas Jakobs: Bitte mehr davon, das dieser ganze Cloud und Abo Dreck schneller beerdigt wird als er gekommen ist…
Ist übrigens auch für die "dezentralen Blockchain-Puristen" problematisch, wenn zig Nodes oder DB's bei den großen Cloud-Anbietern laufen.
Frei nach dem Motto: Wenn die Konzerne alle Schienentrassen besitzen, sollte sich kein Zugnetz wirklich dezentral und unabhängig vermarkten.
Schön wärs ja. Aber wie willst Du das erzwingen? Ich kann mich nicht erinnern, dass die Nutzer dieses Modell ausdrücklich gefordert haben. Autodesk hat hingegen eine super Einnahmequelle vorausgesehen, die Entwicklung und den Verkauf der Software mit Dauerlizenz eingestellt, und die Nutzer eher erpresst. Entweder Mietlizenz oder halt nicht bzw. weiter ein dahinsiechendes Pferd reiten.
Wenn Du jetzt mit den Füßen abstimmst und "dann halt nicht" wählst, gefährdest Du mit Sicherheit das eigene Unternehmen in kurzer Zeit noch mehr als mit den Cloud-/Miet-Lizenzen. Die Abhängigkeiten von so manchem Schlüsselprodukt wie CAD wurde bereits vor vielen Jahren erzeugt, da war diese Masche in heutiger Ausprägung noch nicht absehbar. Zu 100% gleichwertige Alternativen existieren nicht, annähernd gleichwertige Alternativen sind entsprechend teuer oder gar teurer und schlagen hinsichtlich Lizenzmodell denselben Weg ein, weil das nun mal die perfekte Einnahmequelle ist.
Die Ursprünge unserer Abhängigkeiten liegen weit, weit zurück. Da stand noch die 19 im vierstelligen Jahr vorne und nicht die 20.
Ich seh gedanklich schon den ganz großen Crash kommen, … danach beleben wir Kuhlmann wieder … und zeichnen am A0 Brett mit Parallelogrammführung …
gut wer noch welche hat und genug Platz sie aufstellen.
und welcher Konstrukteur könnte damit umgehen?
Hab eine, steht voll einsatzbereit herum und ist auch nicht zugebaut. Zeit zur Inbetriebnahme. Das Schmucke Großformat-Foto abhängen, leeres Blatt dranhängen und loslegen. Nur die Lichtpausmaschine ist nimmer da. Obwohl die gar nicht so groß war, war sie doch im Weg :(
DoctoLib zickt heute auch noch mehr rum als sonst.
("Wir haben uns für AWS (Amazon Web Services) als Datenhosting-Lösung entschieden, da es sich um eine der fortschrittlichsten und sichersten Lösungen auf dem Markt handelt.")
Der DoctorLip ist eh überbewertet – wenn die TI steht, ist es eh Essig mit Terminen, fortschrittlichste Lösung hin oder her. Früher hieß es: "Er fuhr Ford und kam nie wieder", "dann kam Boris Becker, bin ich schon drin …" – heute gibt: "ich habe AWS und komm nicht rein". Zeiten ändern sich, aber auch dieser Weckruf wird am Lauf der Lemminge nichts ändern.
ROFL, Günter … Ich kenne noch Ford, die AOL-Werbung von Bobbele, natürlich AWS und auch die Lemmings hab ich mit Stoppern, Treppenbauern und Fallschirmspringern gerettet. Mist, ich werde alt … und unsere Ansichten sind oldschool, outdated und prepp'ig. Aber sie haben sich bewährt! :-)
Ich habe spätestens dann bzgl. Cloud, Softwareabos etc umgedacht, als Microsoft vor etlichen Jahren das originale Lemmings rückwirkend nicht nur aus dem MS-Store sondern auch dessen lokale Installation von den Rechnern entfernt hat. 🤪
Duolingo ist Stand 17:45 Uhr weiterhin down. Wehe, das versaut mir meinen 2400-Tage-Streak Spanisch!
Hat eigentlich schon mal Jemand "Kippunkte" für das Internet/IT definiert?
Also Sachen die wirklich dazu führen können, dass die Kacke mal richtig am dampfen ist? In irgendwelchen Problemsituationen braucht man noch Zugriff auf Informationen/Dienste, wenn die aber zu dem Zeitpunkt gar nicht funktionieren. Am Ende kann man alles irgendwie fixen, aber der Schaden ist da.
Im privaten Bereich gibt es auch so Sachen, wenn man das Passwort für die Passwortdatenbank auf dem NAS hat, noch 5 Backups hat aber ohne Passwort nicht auf Backup/NAS kommt.
Simples Beispiel: Kein Zugang zu WM-Fussballspiel ohne FIFA-App mit FIFA-Konto. Wenn da Dein Handy keinen Zugriff hat, bleibst Du draussen und verpasst das Spiel.
Bei meiner Mutterorganisation hat es sämtliche Systeme außer betrieb gesetzt einschließlich die gesamte Telefonanlage… wir konnten nur sehr eingeschränkt arbeiten bis ca. 13 Uhr danach wurde es stetig besser und gegen 14 Uhr lief alles wieder.
PKW Prüforganisation
Frag mal nach, ob/was die Mutterorganisation daraus gelernt hat.
Ohne AutoCAD könnte ich leben – viel schlimmer ist, dass auch Strava betroffen ist 😩
DNS0.eu ist auch am Ende. :(
Das hat jetzt aber weniger was mit dem AWS-Ausfall zu tun.
Was ich an der ganzen Sache schon auch interessant finde:
AWS erläutert zwar auf
https://health.aws.amazon.com/health/status?path=service-history
in Trippelschritt-Updates, was sie veranstalten, um alles wieder zum Laufen zu bringen und wo/was gehakt hat, aber es gibt weder ein Wort des Bedauerns geschweige denn eine Entschuldigung noch eine Erklärung, warum das überhaupt passieren konnte.
Health.autodesk.com liefert immernoch stand 9:30 Uhr fast 24h nach dem Beginn der Störung satte 61 Produktunterbrechungen. Die Lizenzierung geht zumindest seit heute Nacht wieder subjektiv fehlerfrei.
Das kann man sich nicht mehr schönreden.. :(
Leider nicht von mir:
"Many cloud systems are actually just distributed single points of failure, despite their marketing."
(aus einem Kommentar bei einem Artikel auf theregister. com)
Sophos Central war teilweise auch betroffen. Wenn man z.b eine API ändern oder hinzufügen wollte war einfach der Button zum hinzuügen weg :-D
Jetzt geht wieder alles
Bin ich wirklich schon so weit weg?
Mein gesamtes Berufsleben (>40 Jahre) habe ich in der IT (früher EDV) verbracht – seit 9 Jahren Privatier – und die AWS-Störung gestern (und wohl teilweise heute noch) geht mir am Allerwertesten vorbei.
PS: Die Betroffenen haben natürlich mein Mitgefühl ;-)
Ganz schlimm vom AWS-Ausfall betroffen: Smart Beds.
Via Mastodon soeben erhalten:
AWS crash causes $2,000 Smart Beds to overheat and get stuck upright
https://odenwald.social/@HeadlessZeke@infosec.exchange/115414256620943270